Prices
Our pricing structure offers customized GPU server solutions with fixed terms or flexible GPU blib instances - by the minute or as a monthly subscription, with invoice and full cost control. All servers are located in the EU and are sustainably manufactured from upcycled components.
Step 1: Choose package
a) Classic servers
Pay monthly by invoice or credit card, for companies only. Provision usually takes place within one working day. Our classic servers are ideal for B2B customers who require comprehensive service and support. Ask AI and GPU experts free questions via E-Mail about CUDA, Python, networking and GPU optimization to get your project up and running as quickly as possible. Classic servers are also available with perfectly preconfigured Windows.
SPAR-BOX
285 €
per month
RAM / VRAM:
SSD:
GPU:
CPU:
TFLOPS:
26 GB + 24 GB
180 GB
RTX 3090
4 Cores
34
POWER-AI
from €479
per month
RAM / VRAM:
SSD:
Sigle/Dual
GPU:
CPU:
TFLOPS:
58 GB + 48 OR 24 GB
600 GB (NVMe)
2x RTX 3090 or
1x RTX 4090 (24 GB)
8 performance cores
68 - 82
EXPLORER
195 €
per month
RAM / VRAM:
SSD:
GPU:
CPU:
TFLOPS:
26 GB ECC + 16 GB ECC
180 GB (NVMe)
RTX A4000
4 perf. cores
20
... or, alternatively, start a GPU server directly:
b) New GPU server blibs
GPU Server Blibs from Trooper.AI are based on the same technology as our classic servers, but are deployed instantly within minutes. They also offer full root access, run on Ubuntu 22 and with 100% GPU power. What's more, our GPU server blibs can be stopped or even frozen permanently at reduced prices. There is no notice period and payment is made conveniently via various payment options using the credit method. So you remain flexible and have your budget under control! From a top-up amount of EUR 1,000, you can also pay by invoice and PO number. Our popular AI and programmer support from the classic packages is available on a subscription basis. If you have any questions, simply call us on 06126 928999-1 or write to us: sales@trooper.ai.
| Blib Name | GPU | CPU RAM | CPU Cores | NVMe | Price starting |
|---|---|---|---|---|---|
| Explorer | 1-2x RTX A4000 | 28 – 98 GB | 4 – 12 | 180 – 900 GB | 0.24/h EUR or 150/m EUR |
| Novadrive | 1-2x Tesla V100 16GB | 32 – 76 GB | 4 – 10 | 180 – 800 GB | 0.29/h EUR or 180/m EUR |
| Conqueror | 1x RTX 4070 Ti Super | 32 – 48 GB | 4 – 6 | 180 – 600 GB | 0.32/h EUR or 200/m EUR |
| Sparbox | 1-2x RTX 3090 | 28 – 58 GB | 2 – 8 | 180 – 600 GB | 0.40/h EUR or 250/m EUR |
| Novatesla | 1-2x Tesla V100 32GB | 42 – 100 GB | 4 – 10 | 270 – 1200 GB | 0.46/h EUR or 290/m EUR |
| Powerai | 1-2x RTX 4090 | 32 – 120 GB | 4 – 16 | 180 – 1200 GB | 0.65/h EUR or 410/m EUR |
| Infinityai | 1-4x A100 40GB | 50 – 356 GB | 4 – 30 | 270 – 2800 GB | 0.90/h EUR or 570/m EUR |
| Darkrock | 1-2x RTX 5090 | 42 – 128 GB | 4 – 16 | 600 – 900 GB | 1.50/h EUR or 950/m EUR |
Step 2: Choose top extras
For classic servers, we offer great upgrades to make the GPU server experience even better:
Step 3: Order
- German contact persons
- Monthly cancelable
- Fast provision
Order today and secure your AI server for your team. If you have any special requests, please call us, we can build any server for you. What are you waiting for?
NEW: Start our servers as a Blib instance and only pay by the hour. Prices start at 0.25 EUR / hour. Start your first Trooper.AI Blib instance now:
Server performance comparison
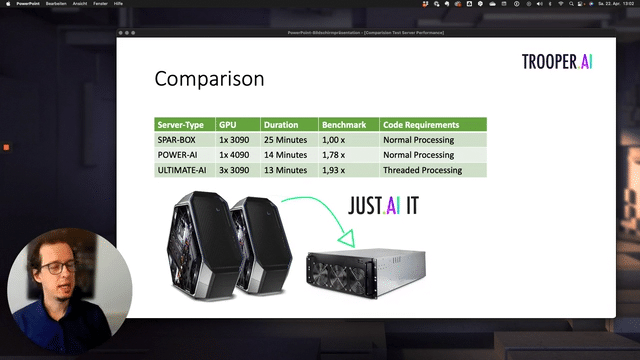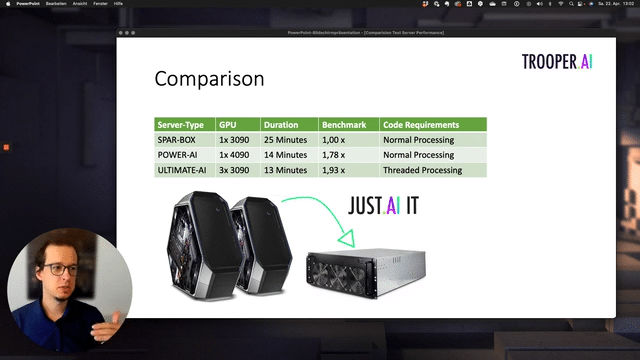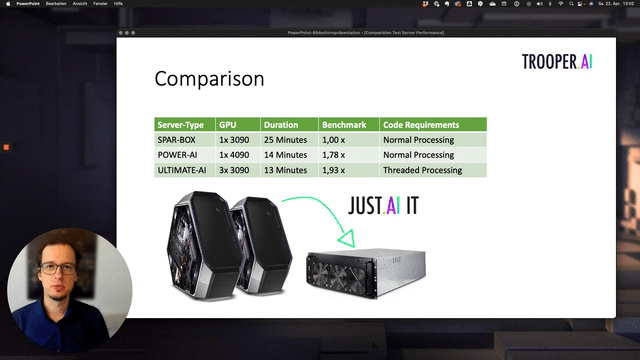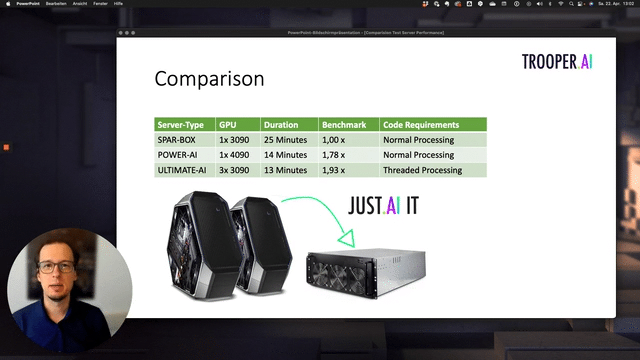
GPU TFLOPS comparison
| GPU | TFLOPS (FP32) | CUDA Cores | Tensor- TFLOPS |
|---|---|---|---|
| RTX 3090 | 34 | 10.496 | 142 |
| RTX 4090 | 82 | 16.384 | 330 |
| RTX A5000 | 28 | 8.192 | 111 |
| NVIDIA V100 | 14 | 5.120 | 125 |
* TFLOPS = single precision (FP32 single precision) with 308 CUDA cores per 1 TFLOP. If specified as FP16 Tensor TFLOPS, then values without sparsity! Not virtualized = 100% AI power hardware! Price per month. 7-day trial with Sparbox Standard with money-back guarantee. Availability of finished systems within 24 hours. Payment by invoice or credit card. All prices exclusively for companies and self-employed persons.
** Tensor TFLOPS is the computing power for special operations for AI in FP16 without sparsity.
GPU practice comparison
| GPU | VRAM | Generation | SDXL: 16 images* | LLM 8b** |
|---|---|---|---|---|
| RTX 5090 | 32 GB | Blackwell | tbd minutes | 128 r_t/s |
| RTX 4090 | 24 GB / 48 GB | Ada | 1:18 minutes | 87 r_t/s |
| A100 | 40 GB | Ampere | 1:19 minutes | 104 r_t/s |
| RTX 4070S Ti | 16 GB | Ada | 2:17 minutes | 56 r_t/s |
| RTX 3090 | 24 GB | Ampere | 2:24 minutes | 69 r_t/s |
| Tesla V100 | 16 GB / 32 GB | Volta | 2:36 minutes | 62 r_t/s |
| RTX 4000 Ada | 20 GB | Ada | 3:06 minutes | 39 r_t/s |
| RTX A4000 | 16 GB | Ampere | 3:37 minutes | 38 r_t/s |
| RTX 4060 TI | 16 GB | Ada | 4:21 minutes | n/a |
* Speed benchmark performed with Automatic1111 v1.6.0 and the following settings: sd_xl_base.1.0 Model, Prompt: "cute maltese puppy on green grass" (no negative prompt), DPM++ 2M Karras, No Refiner, No Hires Fix, CFG Scale: 7, Steps: 30, 1024×1024, Batch Count: 4, Batch Size: 4, Random Seed, PNG Images.
** LLM speed benchmark performed with OpenWebUI installation without customizations. Context length: 2048 (default). No system prompt. Request prompt: "Name the 5 biggest similarities between a wild tiger and a domestic cat.", Model Small: llama3.1:8b-instruct-q8_0, Best of 3 runs, Response Tokes per Seconds, Higher is faster or more powerful
What is the difference to Tensor TFLOPS?

Tensor TFLOPS is a measure specifically for machine learning on GPUs. Here, computing power is only evaluated in the context of ML computation and everything else is left out. Since the RTX cards from NVIDIA for this purpose contain special components in the chips, they are particularly fast and very suitable for this. As an automobile comparison, you can imagine a winter tire, it has very good characteristics in the snow and brings your car to a stop faster. But in summer it is just a "normal" tire without special features. Winter tire = RTX, winter = ML application, RTX + ML = Tensor! The equation is as simple as that and if that still doesn't help you, we will be happy to advise you personally. Because personal contact is important to us!
We use Single Precision in our power calculation. The booked performance in Tensor TFLOPS is mostly factor 8, so booked 34 TFLOPS then become over 272 Tensor TFLOPS in your ML application! Completely free of charge, ingenious or? We will be happy to advise you on the phone.
WHAT ARE YOU WAITING FOR?
7 days money back guarantee
7 days the money back for 1x GPU servers. Special builds excluded.
Now also available as a blib. Learn more:
Cost-effective AI hardware from used gaming components: Rent your AI server or GPU workstation now

Our AI servers and GPU workstations are so favorablebecause we assemble them from used gaming components. Instead of buying expensive new hardware, we use the power of existing components and build powerful AI systems from them. This saves us money on hardware procurement and allows us to pass these savings on to our customers.
In addition, we offer our AI servers and GPU workstations exclusively for rent instead of selling them. This gives our customers the flexibility to adapt the system to their current needs at any time without committing themselves permanently to a specific system. This flexibility and cost efficiency makes us a particularly attractive AI hardware supplier.
In summary, we offer a unique combination of performance and cost efficiency by leveraging used gaming components and offering our AI systems for rent. Our customers can access powerful GPUs without having to dig deep into their pockets.
7 days any time the money back, guaranteed!
Or rent by the hour and start immediately: